 |
| ARIMA dengan R |
Jumpa lagi teman-teman, sebelumnya saya mohon maaf karena kemarin tidak sempat membuat unggahan terbaru di blog ini. Baik, sebelumnya kita telah mengulas tentang pemodelan Geographically Weigthed Regression (GWR) dengan R. Kali ini, kita akan melanjutkan belajar bersama mengenai pemodelan yang tak asing lagi dan populer hingga kini, yaitu pemodelan Autoregressive Integrated Moving Average (ARIMA).
Kita akan membahas ARIMA secara langsung tanpa membahas AR dan MA secara tersendiri mengingat pada dasarnya ARIMA adalah model perpaduan antara model AR dengan order p, MA dengan order q dan aspek differencing dengan order d. Artinya, ketika kita mendengar istilah AR(1), maka sebenarnya itu adalah ARIMA(1, 0, 0), ketika kita mendengar ARI(1,1), maka aslinya itu ARIMA(1, 1, 0), atau bila mendengar MA(3), itu sebenarnya ARIMA(0, 0, 3) atau IMA(2,1) sebenarnya adalah ARIMA(0, 2, 1).
Data runtun waktu atau time series merupakan salah satu jenis data yang hingga kini banyak digunakan dalam penelitian. Popularitas jenis data ini disebabkan karena manfaat yang dapat kita peroleh selain mampu mengamati pola data serta historis data, kita dapat pula melakukan estimasi atau peramalan menggunakan data tersebut yang dipengaruhi oleh masa lalu data itu sendiri. Beberapa contoh kasus nyata bahwa suatu data dapat dipengaruhi oleh dirinya sendiri pada periode sebelumnya atau masa lalunya adalah inflasi, indeks harga saham, sentimen, atau yang akan kita gunakan datanya dalam praktik kali ini yaitu pertumbuhan ekonomi.
Bagaimana dengan batasan titik waktu yang harus digunakan dalam pemodelan ARIMA? Sebenarnya untuk jumlah titik waktu minimal yang dapat digunakan pemodelan ARIMA ini hingga kini masih dalam perdebatan. Menurut Pyndick dalam bukunya Makroekonomi minimal 30 titik waktu, namun kita ambil pilihan amannya, semakin banyak titik waktu yang digunakan akan semakin baik model ARIMA yang kita peroleh, berapa jumlah titik waktunya? Ukuran relevannya adalah dengan data runtun waktu yang kita gunakan, kita telah mampu menangkap pola dari data tersebut secara visual, misalkan pola musiman, pola harian, pola tahunan, pola trend, atau pola campuran. Ketika dari sekian periode waktu data itu, kita telah mampu mendiagnosa pola datanya, sebenarnya kita telah cukup untuk digunakan dalam pemodelan ARIMA. Namun jika dengan data yang tersedia, terdapat waktu-waktu di mana data kita menunjukkan pola yang tidak pasti atau dalam ketidakpastian, maka ada baiknya memang jumlah titik waktu data atau series datanya ditambah.
Kita kembali ke ARIMA, jadi di dalam pemodelan ARIMA ini, kita akan dihadapkan dengan istilah-istilah unik, misalnya stasioneritas data. Sebuah data dikatakan stasioner bila rata-rata dan varians data tersebut tidak beruba-ubah (berfluktuasi) seiring dengan perubahan waktu atau periodenya. Kondisi ini kemudian memunculkan istilah stasioner dalam rata-rata (mean) dan varians (ragam). Dalam penerapannya di R, uji stasioneritas biasanya menggunakan uji Augmented Dicky Fuller (ADF) yang merupakan uji pengembangan dari Dicky Fuller (DF). Fungsi uji ADF dalam R terdapat di dalam package tseries.
Bila sebuah data tidak stasioner pada level atau data aslinya (d = 0), maka kita akan menggunakan bentuk differencing data aslinya untuk kemudian diuji kembali stasioneritasnya. Bila didapatkan nilai p-value < alpha penelitian, maka dikatakan bahwa data telah stasioner. Bila data stasioner pada level maka nilai d = 0, jika stasioner pada differencing 1, maka d = 1, dan seterusnya. Khusus untuk mengantisipasi data yang kita gunakan tidak stasioner dalam varians, kita dapat menggunakan data hasil transformasi Box-Cox sebagaimana yang telah kita pelajari pada unggahan transformasi variabel di blog ini. Kendati demikian, transformasi Box-Cox ini hanya mampu mengakomodir data yang bernilai positif saja, sedangkan untuk data pertumbuhan yang mengandung nilai negatif tidak bisa dan bahkan saya menemukan eror dalam eksekusi di R. Maka solusi alternatifnya bisa kita gunakan transfromasi invers Box-Cox.
Lantas bagaimana cara mendiagnosa order AR dan MA? Untuk mendiagnosa order AR kita mengacu pada sebaran data kelemabaman dari Partial Autocorrelation Function (PACF), sedangkan order MA dapat kita diagnosa berdasarkan sebaran data kelemabaman Autocorrelation Function (ACF). Berapa nilai order yang menjadi kandidat model AR dan MA? kita amati setiap garis yang melewati batas garis Bartlett sebaran data kelambaman ACF dan PACF tadi.
Setelah ordernya kita tentukan, tahapan selanjutnya adalah mengestimasi model ARIMA yang memungkinkan. Dalam R kita dapat menggunakan fungsi auto.arima() atau pemodelan secara manual dengan fungsi Arima() di dalam package forecast. Setelah seluruh kandidat model telah dimodelkan, berikutnya kita cek performa model dan akurasinya untuk mendapatkan model terbaik (best model). Adapun kriteria atau ukuran pemilihan model terbaik bisa berdasarkan nilai RMSE, MAE, MAPE, R Square, Akaike Information Criteria (AIC), atau Bayessian Information Criteria (BIC), atau ukuran lainnya. Namun, dalam praktik kali ini kita pilih model terbaiknya berdasarkan nilai RMSE terkecil.
Ketika model terbaik telah terpilih, maka selanjutnya kita dapat melakukan peramalan untuk beberapa periode selanjutnya dengan titik waktu sesuai kebutuhan analisis dengan menggunakan fungsi forecast() dalam package forecast.
Oke, demikian sekilas pengantar ARIMA, selanjutnya kita akan coba mempraktikkan bagaimana pemodelan ARIMA dengan R. Terlebih dulu kita akan siapkan data yang akan kita gunakan, yaitu data laju pertumbuhan ekonomi Jawa Timur Triwulanan, mulai Triwulan I-2011 hingga Triwulan IV-2021 pada tautan berikut. Setelah datanya telah kita unduh, pemodelan ARIMA dengan R dapat mengikuti beberapa code berikut:
Code:
#Import data laju pertumbuhan ekonomi Jatim Triwulan 1/2011- Triwulan IV/2021
library(readxl)
lpejatim <- read_excel("C:/Users/Joko Ade/Downloads/lpejatim2021.xlsx")
#Mengattach data
attach(lpejatim)
#Melihat sekilas data
str(lpejatim)
unlist(lpejatim)
as.numeric(lpejatim$Y)
head(lpejatim)
Hasil:
tibble [44 x 1] (S3: tbl_df/tbl/data.frame)
$ Y: chr [1:44] "6.89" "6.40" "6.06" "6.43" ...
Y1 Y2 Y3 Y4 Y5 Y6 Y7 Y8 Y9 Y10 Y11 Y12 Y13
"6.89" "6.40" "6.06" "6.43" "6.49" "6.62" "6.86" "6.59" "6.17" "5.84" "5.72" "6.59" "5.85"
Y14 Y15 Y16 Y17 Y18 Y19 Y20 Y21 Y22 Y23 Y24 Y25 Y26
"5.93" "6.14" "5.52" "5.20" "5.41" "5.43" "5.71" "5.58" "5.81" "5.64" "5.27" "5.37" "5.05"
Y27 Y28 Y29 Y30 Y31 Y32 Y33 Y34 Y35 Y36 Y37 Y38 Y39
"5.64" "5.76" "5.41" "5.56" "5.39" "5.53" "5.60" "5.80" "5.33" "5.40" "2.90" "-5.86" "-3.47"
Y40 Y41 Y42 Y43 Y44
"-2.65" "-0.44" "7.07" "3.27" "4.59"
[1] 6.89 6.40 6.06 6.43 6.49 6.62 6.86 6.59 6.17 5.84 5.72 6.59 5.85 5.93 6.14 5.52 5.20
[18] 5.41 5.43 5.71 5.58 5.81 5.64 5.27 5.37 5.05 5.64 5.76 5.41 5.56 5.39 5.53 5.60 5.80
[35] 5.33 5.40 2.90 -5.86 -3.47 -2.65 -0.44 7.07 3.27 4.59
Code:
#konversi ke data runtun waktu
#frekuensi = 4 karena triwulanan
lpe_y <- ts(Y, start = c(2011,1), frequency = 4)
#melihat data runtun waktu
lpe_y
str(lpe_y)
Hasil:
Qtr1 Qtr2 Qtr3 Qtr4
2011 6.89 6.40 6.06 6.43
2012 6.49 6.62 6.86 6.59
2013 6.17 5.84 5.72 6.59
2014 5.85 5.93 6.14 5.52
2015 5.20 5.41 5.43 5.71
2016 5.58 5.81 5.64 5.27
2017 5.37 5.05 5.64 5.76
2018 5.41 5.56 5.39 5.53
2019 5.60 5.80 5.33 5.40
2020 2.90 -5.86 -3.47 -2.65
2021 -0.44 7.07 3.27 4.59
Time-Series [1:44] from 2011 to 2022: 6.89 6.40 6.06 6.43 ...
Code:
#Visualisasi grafik garis
plot(lpe_y, col = "blue", lwd = 1, main = "Laju Pertumbuhan Ekonomi Jawa Timur \nTw I/2011 - Tw IV/2021 year on year", xlab = "Periode",
ylab = "persen")
#Membubuhi grid pada grafik
grid()
#memberi garis vertikal warna putus-putus pada grafik
abline(v =2020.2, col = "red", lty=2)
#menambahkan teks keterangan pada garis vertikal merah
text(2019.2, 0, c("Efek Kebijakan PSBB"))
Hasil:
 |
| Visualisasi 1 |
Code:
#Uji Stasioneritas pada mean
library(tseries)
adf.test(lpe_y)
#uji stasioneritas pada varians (ragam)
require(car)
lamdafm1 <- boxCox(lpe_y~1, family = "yjPower")
lamdamod <- lamdafm1$x[which.max(lamdafm1$y)]
library(forecast)
lpe_box <- forecast(as.numeric(lpejatim$Y), lambda = lamdamod)
lpe_bc <- lpe_box$fitted
Hasil:
Augmented Dickey-Fuller Test
data: lpe_y
Dickey-Fuller = -4.3265, Lag order = 3, p-value = 0.01
alternative hypothesis: stationary
 |
| Nilai Lambda Box-Cox |
Yang digunakan selanjutnya adalah lpe_bc
Code:
#Identifikasi Model Arima dan Plot ACF dan PACF
par(mfrow=c(2, 1))
acf(lpe_bc)
pacf(lpe_bc)
Hasil:
 |
| Diagnosa order ARIMA dari plot ACF dan PACF |
Code:
#Memodelkan arima
arima1 <- Arima(lpe_bc, order = c(1, 1, 3), include.drift = F)
arima2 <- Arima(lpe_bc, order = c(1, 1, 2), include.drift = F)
arima3 <- Arima(lpe_bc, order = c(1, 1, 1), include.drift = F)
arima4 <- Arima(lpe_bc, order = c(1, 1, 3), include.drift = T)
arima5 <- Arima(lpe_bc, order = c(1, 1, 2), include.drift = T)
arima6 <- Arima(lpe_bc, order = c(1, 1, 1), include.drift = T)
#Performa model
library(performance)
cbind(Model = c("arima1_113WD", "arima2_112WD", "arima3_111WD", "arima4_113D", "arima5_112D", "arima6_111D"),
rbind(performance(arima1), performance(arima2), performance(arima3), performance(arima4),
performance(arima5), performance(arima6)))
#Akurasi Model
cbind(Model = c("arima1_113WD", "arima2_112WD", "arima3_111WD", "arima4_113D", "arima5_112D", "arima6_111D"),
rbind(accuracy(arima1), accuracy(arima2), accuracy(arima3), accuracy(arima4),
accuracy(arima5), accuracy(arima6)))
Hasil:
Model AIC BIC RMSE Sigma
1 arima1_113WD 172.4274 181.2334 1.551617 1.648081
2 arima2_112WD 171.0174 178.0622 1.561728 1.637954
3 arima3_111WD 169.0502 174.3338 1.549629 1.605322
4 arima4_113D 171.1483 181.7155 1.456645 1.567431
5 arima5_112D 170.0821 178.8881 1.468487 1.559783
6 arima6_111D 170.9937 178.0385 1.548613 1.624199
Model ME RMSE MAE
Training set "arima1_113WD" "-0.259609486763692" "1.55161669987552" "0.671955748856711"
Training set "arima2_112WD" "-0.241673526778238" "1.56172802583685" "0.65957405897493"
Training set "arima3_111WD" "-0.0552082070266032" "1.54962865789642" "0.692723965049203"
Training set "arima4_113D" "0.0803514319937035" "1.45664538456452" "0.727631232089374"
Training set "arima5_112D" "0.0992586023896908" "1.46848703826404" "0.756376385151208"
Training set "arima6_111D" "0.00023447190214626" "1.54861284512487" "0.688015537688339"
MPE MAPE MASE ACF1
Training set "2.78490489815687" "17.1241960247521" "1.06356838866507" "-0.0895988988457491"
Training set "3.61167160071564" "16.8526596491993" "1.04397070834323" "-0.0275484078350913"
Training set "-0.591718127659727" "17.4012301341839" "1.09644022325965" "-0.0799684281753089"
Training set "9.4241238117586" "17.3589874339763" "1.15169128082078" "-0.0614280088800428"
Training set "11.0168221505381" "17.6050937493751" "1.19718897345296" "-0.0430505221739149"
Training set "0.113333421180444" "17.3254527504112" "1.0889877466496" "-0.0800315290870742"
Code:
#Uji Signifikasi Model Arima
library(lmtest)
rbind(cbind(Model = c("arima1_113WD"),rbind(coeftest(arima1))),
cbind(Model = c("arima2_112WD"),rbind(coeftest(arima2))),
cbind(Model = c("arima3_111WD"),rbind(coeftest(arima3))),
cbind(Model = c("arima4_113D"),rbind(coeftest(arima4))),
cbind(Model = c("arima5_112D"),rbind(coeftest(arima5))),
cbind(Model = c("arima6_111D"),rbind(coeftest(arima6))))
Hasil:
Model Estimate Std. Error z value Pr(>|z|)
ar1 "arima1_113WD" "0.636286741337564" "0.449053441049423" "1.41695104228705" "0.156497241726144"
ma1 "arima1_113WD" "-0.419573044318619" "0.460601485844076" "-0.910924209351452" "0.362335308848335"
ma2 "arima1_113WD" "-0.800891249391554" "0.193247621699613" "-4.14437829737679" "3.40736855884907e-05"
ma3 "arima1_113WD" "0.352319589531121" "0.352257530521445" "1.00017617511139" "0.317225256934432"
ar1 "arima2_112WD" "0.0378948644684753" "0.295683694715215" "0.12816014256374" "0.898022241521018"
ma1 "arima2_112WD" "0.143113146939234" "0.281474408184658" "0.508441061701587" "0.61114406248608"
ma2 "arima2_112WD" "-0.706199595456142" "0.169172931135828" "-4.17442430485015" "2.98740524659347e-05"
ar1 "arima3_111WD" "-0.634075276768642" "0.127015437988826" "-4.99211187874991" "5.97226418857177e-07"
ma1 "arima3_111WD" "0.999999877748336" "0.067114488567726" "14.8999105720551" "3.30020911121018e-50"
ar1 "arima4_113D" "0.580617375518388" "0.326779107733077" "1.77678854546801" "0.0756030372083661"
ma1 "arima4_113D" "-0.493567262310261" "0.349083581049896" "-1.4138942336555" "0.157392959282349"
ma2 "arima4_113D" "-0.862153783283784" "0.180703835364512" "-4.77108735154772" "1.83234049334131e-06"
ma3 "arima4_113D" "0.355725447777676" "0.333809752697306" "1.06565324980257" "0.286580418226939"
drift "arima4_113D" "-0.121719569017145" "0.0444373506687291" "-2.73912749489811" "0.00616024792593575"
ar1 "arima5_112D" "0.171766595217114" "0.186618023289883" "0.920418039956951" "0.357354345010246"
ma1 "arima5_112D" "-0.113718270169818" "0.167655681566651" "-0.678284619448518" "0.497591248730932"
ma2 "arima5_112D" "-0.886272428131124" "0.16250746519766" "-5.45373363034822" "4.93230691444996e-08"
drift "arima5_112D" "-0.124376284025448" "0.0384252558337676" "-3.23683684927214" "0.00120862489519324"
ar1 "arima6_111D" "-0.634080545480926" "0.126927940941883" "-4.99559467187176" "5.86547403550869e-07"
ma1 "arima6_111D" "0.999999571312214" "0.0673260320919646" "14.8530893658824" "6.64351382618105e-50"
drift "arima6_111D" "-0.069295087857588" "0.291670145614196" "-0.237580324553502" "0.812206612354163"
Code:
#Model terbaik berdasarkan RMSE terkecil
arima <- arima5
#Melakukan Peramalan h = berapa titik yang akan diramal
fc <- forecast(arima, h = 4)
#Ploting secara keseluruhan termasuk hasil forecast
par(mfrow=c(1,1))
plot(forecast(arima, h = 4))
Hasil:
 |
| Plot hasil peramalan dengan model ARIMA terbaik |
Code:
#Mendiagnosa hasil pemodelan
tsdiag(arima)
#Mengenerate Resid2 setiap model
resid2 <- arima$residuals
#Melakukan uji nilai tengah residuals dengan uji t
t.test(resid2, mu = 0, alternative = "two.sided")
Kalau p-value uji t > alpha penelitian maka aman
#Melihat Akurasi Peramalan
accuracy(arima)
Hasil:
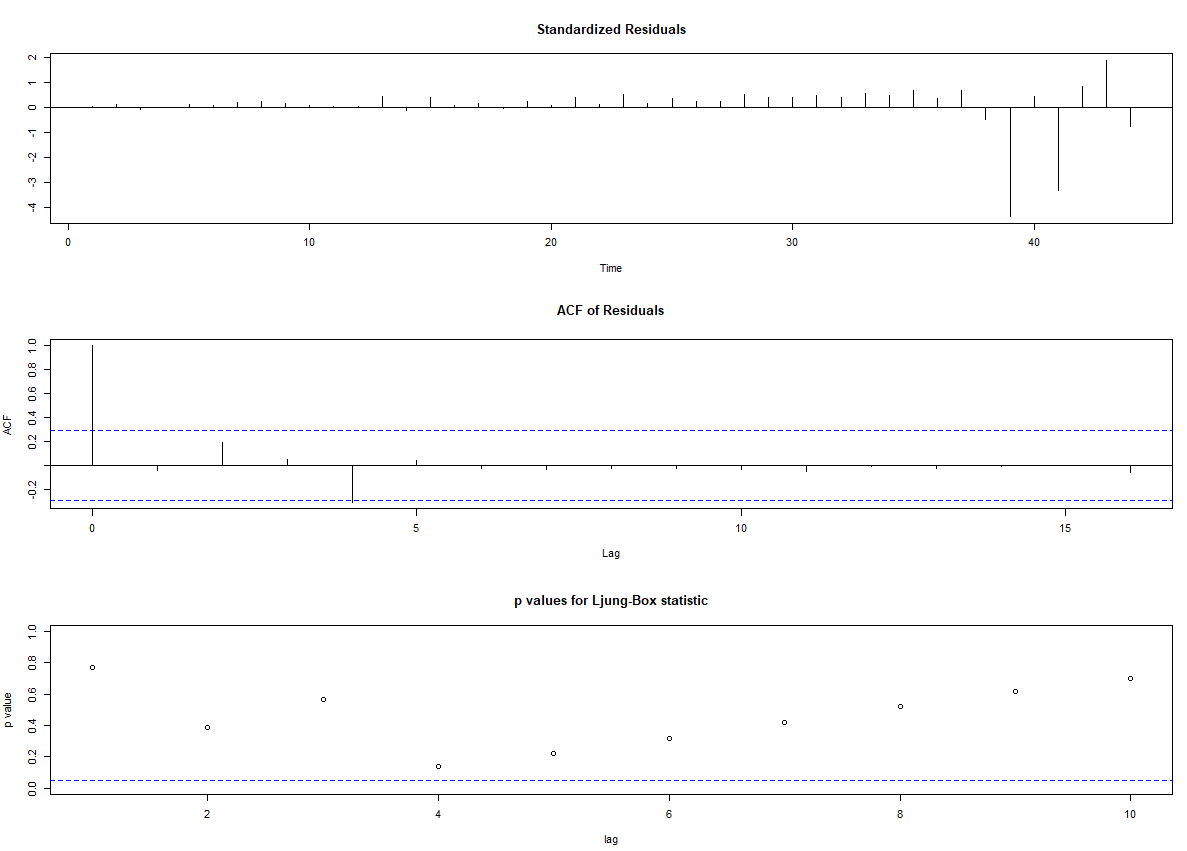 |
| Hasil diagnosa kenormalan residual ARIMA terpilih |
One Sample t-test
data: resid2
t = 0.44425, df = 43, p-value = 0.6591
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
-0.3513310 0.5498482
sample estimates:
mean of x
0.0992586
Terlihat residual terlihat normal
Code:
#Melihat R Square Model Fit
library(caret)
pred <- arima$fitted
R2(pred, as.numeric(lpejatim$Y))
Hasil:
[1] 0.2345608
nilai R square ARIMA terpiliha kita sebesar 23,45 persen
Code:
#Menampilkan Prediksi dan nilai asli
library(ggfortify)
lpepred <- as.numeric(pred)
lpeaktual <- as.numeric(lpejatim$Y)
predtrueval <- data.frame(lpepred, lpeaktual)
predtrueval.ts <- ts(predtrueval)
theme_set(theme_bw())
autoplot(predtrueval.ts,xlab = "Periode", ylab = "Laju Pertumbuhan Jawa Timur yoy") +
ggtitle("Plot Prediksi dan Data Aktual Laju Pertumbuhan Ekonomi Jawa Timur") +
theme(plot.title = element_text(hjust = .5))
Hasil:
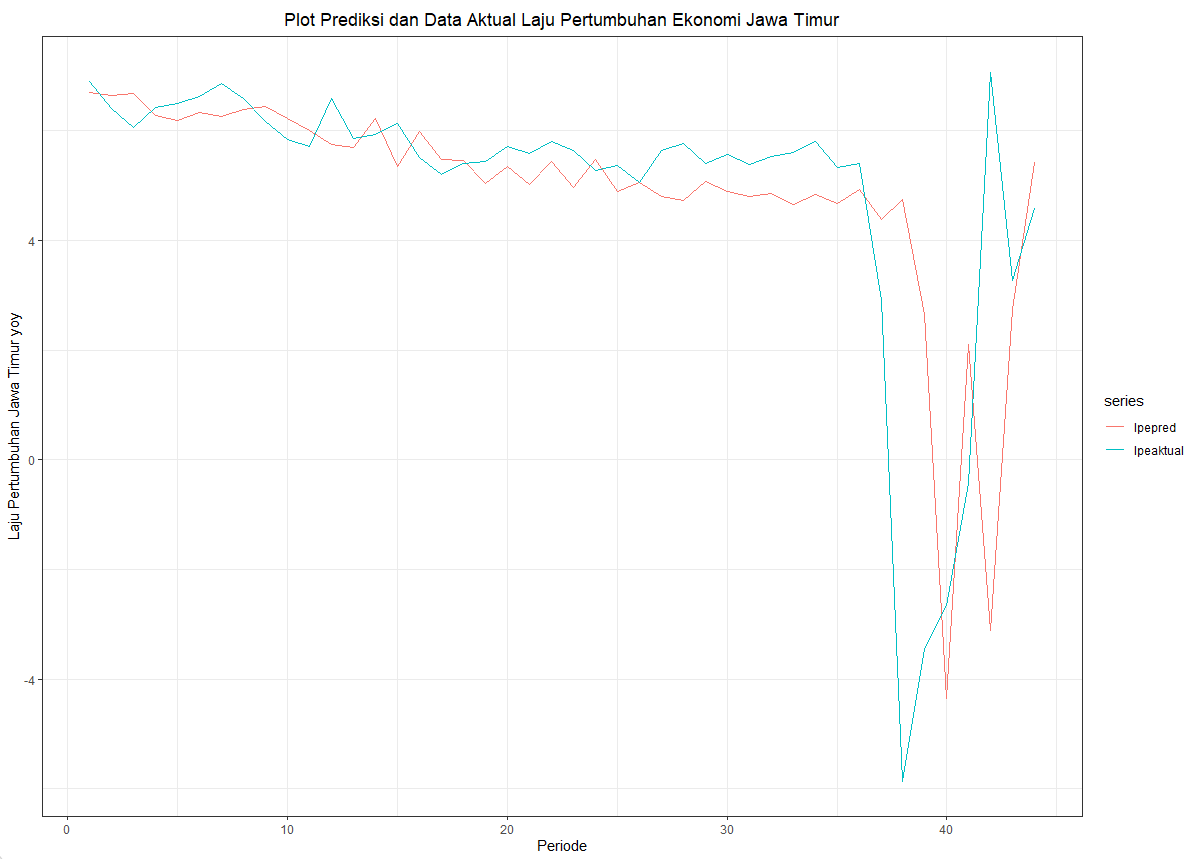 |
| Plot hasil peramalan dan prediksi dengan model ARIMA terpilih |
Demikian sekilas pemodelan ARIMA dengan R. Jangan lupa share dan bertanya bila ada di kolom komentar. Selamat mempraktikkan!