 |
| Regresi Robust |
Setelah sebelumnya kita mengulas mengenai regresi linier, logistik, probit, dan tobit, kali ini kita akan beranjak membahas mengenai pemodelan menggunakan regresi robust (Robust regression model). Bagi yang pernah menggunakan model ini dalam penelitiannya, saya rasa telah paham sampai ke akar-akarnya, namun dalam kesempatan kali ini kita akan mencoba belajar bersama bagaimana definisi dan bagaimana langkah-langkah melakukan pemodelan regresi robust menggunakan R.
Sebelum pemodelan, ada baiknya kita ke pengertian atau teori terlebih dahulu. Jadi, regresi robust ini bermula dari pro dan kontra tentang pencilan (outlier) yang berada di dalam model regresi, apakah harus dibuang atau justru mengikutkannya di dalam model. Dalam bahasan-bahasan sebelumnya, telah kita dapatkan simpulan bahwa membuang atau menghapus pencilan data perlu mempertimbangkan beberapa aspek. Salah satunya adalah ketika kita membuang pencilan begitu saja, terdapat risiko informasi yang akan kita peroleh dari data dan model akan berkurang. Dalam beberapa kasus penelitian, bisa jadi pencilan yang masuk di dalam model justru memperkaya bahkan mampu mempertajam analisis statistik. Sebagaimana menurut Draper dan Smith (1992), bahwa pencilan itu adakalanya memberikan informasi lebih yang justru tidak diberikan oleh titik data lainnya. Mengingat pencilan tersebut memiliki kemampuan memunculkan tambahan informasi, ragam analisisnya bisa jadi lebih mendalam dan menurut Draper dan Smith bisa menjadi bahan penelusuruan data yang lebih jauh.
Dari pro dan kontra itulah kemudian para ahli statistika mengembangkan model regresi yang mampu mengakomodir pencilan di dalam data atau modelnya dan diberi nama regresi robust (Robust regression model). Artinya, bila di dalam pemodelan regresi dengan metode estimasi Ordinary Least Square (OLS), kita menemukan adanya gangguan pencilan, maka regresi robust ini dapat dijadikan sebagai model alternatif.
Adapun gangguan yang disebabkan oleh adanya pencilan di dalam data atau model dapat kita deteksi melalui sebaran residual model dan nilai aktual variabel dependennya. Namun, tidak cukup itu, penekanan utama penggunaan regresi robust ini juga didasarkan pada seberapa penting sebuah atau beberapa pencilan itu berada di dalam data atau model. Dengan kata lain, jika sebuah pencilan itu ternyata tidak penting, maka regresi robust tidak relevan untuk dijadikan sebagai model alternatif setelah regresi OLS.
Dalam praktiknya, untuk mengukur seberapa penting sebuah atau beberapa pencilan kita pertahankan berada di dalam model adalah dengan melihat sebaran nilai difference in fits atau DFFITS-nya. Bila dari sebaran nilai DFFITS ada amatan yang ternyata signifikan secara statistik atau nilainya melampaui threshold DFFITS yang nilainya sebesar 2*sqrt(p/n) (p adalah jumlah variabel independen di dalam model dan n adalah jumlah amatan data), maka dikatakan bahwa pencilan dalam data atau model kita signifikan dan penting untuk dipertahankan berada di dalam model.
Selanjutnya, kita akan membahas mengenai jenis-jenis model regresi robust. Jadi, sejauh ini model regresi robust yang pernah saya gunakan dan saya coba adalah regresi robust dengan metode estimasi S-regression, M-regression, dan MM-regression yang kalau penerapannya di R itu menggunakan 3 pacakge yang berbeda, M-regression menggunakan package MASS, S-regression dengan package robust, dan MM-regression menggunakan package robustbase.
Apa saja kelebihan dari masing-masing metode estimasi model regresi robust? M-regression itu kelebihannya cenderung lebih sensitif terhadap leverage (sensitif terhadap nilai prediktor yang ekstrem atau lebih tinggi dibandingkan lainnya). S-regression memiliki kelebihan mampu menangani adanya leverage hanya saja memiliki efisiensi yang lebih rendah dibandingkan M-regression. Dengan kemampuan tersebut, S-regression biasanya mampu digunakan jika terhadap pencilan model yang lebih dari 50 persen. Sedangkan MM-regression merupakan gabungan dari kedua metode estimasi M dan S sehingga lebih resisten terhadap leverage dan memiliki efisiensi yang lebih tinggi.
Baik, itu sekilas definisi dan sekligus perbedaan masing-masing metode estimasi modelnya. Berikutnya kita akan mempraktikkan bagaimana pemodelan regresi robust ini dengan menggunakan R. Untuk keperluan praktik, saya telah menyiapkan data yang bersumber dari IMDB berupa data pendapatan kotor perfilman dunia, jumlah reviu penonton, dan lainnya untuk praktik regresi robust kali ini. Teman-teman dapat mengunduhnya terlebih dulu pada tautan berikut. Setelah diunduh, pemodelan regresi robust dapat kita lakukan dengan menggunakan code berikut:
Code:
#import Data
library(readxl)
dataku <- read_excel("C:/Users/Joko Ade/Downloads/dfilm.xlsx")
#Melihat sekilas data dan strukturnya
head(dataku)
str(dataku)
Hasil:
rating votgross ur cr metascore duration grossinc
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 8.4 999521 94000 583 78 181 858.
2 7.4 435034 22000 434 69 129 391.
3 6.8 515223 73000 534 64 123 427.
4 8.3 525395 32000 513 78 119 159.
5 6.5 417472 79000 519 53 141 515.
6 6.2 168062 31000 395 54 128 62.2
tibble [71 x 7] (S3: tbl_df/tbl/data.frame)
$ rating : num [1:71] 8.4 7.4 6.8 8.3 6.5 6.2 6.9 6.7 6.7 7.3 ...
$ votgross : num [1:71] 999521 435034 515223 525395 417472 ...
$ ur : num [1:71] 94000 22000 73000 32000 79000 31000 11000 1000 795 28000 ...
$ cr : num [1:71] 583 434 534 513 519 395 362 251 139 383 ...
$ metascore: num [1:71] 78 69 64 78 53 54 64 58 40 53 ...
$ duration : num [1:71] 181 129 123 119 141 128 95 123 118 122 ...
$ grossinc : num [1:71] 858 391 427 159 515 ...
Code:
#mengattach data
attach(dataku)
#Regresi OLS
ols <- lm(grossinc ~ rating + ur + cr + duration + metascore + votgross)
summary(ols)
Hasil:
Call:
lm(formula = grossinc ~ rating + ur + cr + duration + metascore +
votgross)
Residuals:
Min 1Q Median 3Q Max
-244.516 -25.288 -1.688 10.382 210.203
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 72.7748384 98.1231548 0.742 0.4610
rating -5.8285092 10.5302095 -0.554 0.5818
ur 0.0011023 0.0009519 1.158 0.2512
cr -0.2287512 0.1330404 -1.719 0.0904 .
duration -0.2834120 0.5587330 -0.507 0.6137
metascore 0.3862424 0.4764716 0.811 0.4206
votgross 0.0007695 0.0001322 5.821 2.05e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 72.98 on 64 degrees of freedom
Multiple R-squared: 0.7481, Adjusted R-squared: 0.7245
F-statistic: 31.68 on 6 and 64 DF, p-value: < 2.2e-16
Code:
#Uji asumsi klasik regresi linier, teman-teman dapat menyimak ulasannya pada unggahan sebelumnya di blog ini
#Uji Asumsi Normalitas residual model
jarque.bera.test(ols$residuals)
#Uji Asumsi Homoskedastisitas
bptest(ols)
#Uji Non Autokorelasi Residual
dwtest(ols)
#Uji Non Multikolinieritas Variabel Bebas Model
ols_vif_tol(ols)
Hasil:
Jarque Bera Test
data: ols$residuals
X-squared = 34.951, df = 2, p-value = 2.573e-08
studentized Breusch-Pagan test
data: ols
BP = 27.782, df = 6, p-value = 0.0001033
Durbin-Watson test
data: ols
DW = 2.0067, p-value = 0.4238
alternative hypothesis: true autocorrelation is greater than 0
Variables Tolerance VIF
1 rating 0.6912590 1.446636
2 ur 0.2070064 4.830769
3 cr 0.1622107 6.164821
4 duration 0.6414572 1.558951
5 metascore 0.4633169 2.158350
6 votgross 0.1504997 6.644534
Interpretasi: seluruh uji asumsi klasik terpenuhi kecuali normalitas dan homoskedastisitas, baru kita cek seberapa penting pencilan dalam model
Code:
#Melihat outlier melalui plot antara nilai aktual y dan residual terstandardisasi
plot(grossinc, rstandard(ols), ylab='Standardized Residuals', xlab='y')
abline(h=0, col = "red", lty = 2)
text(850,3, c("Outlier"), col = "blue")
text(530,3, c("Outlier"), col = "blue")
#Plot DFFITS masing-masing amatan
plot(nilai_dffits, type = 'h')
#Menambahkan Garis Threshold pada Plot
abline(h = threshold, lty = 2)
abline(h = -threshold, lty = 2)
Hasil:
 |
| Visualisasi keberadaan pencilan dalam model |
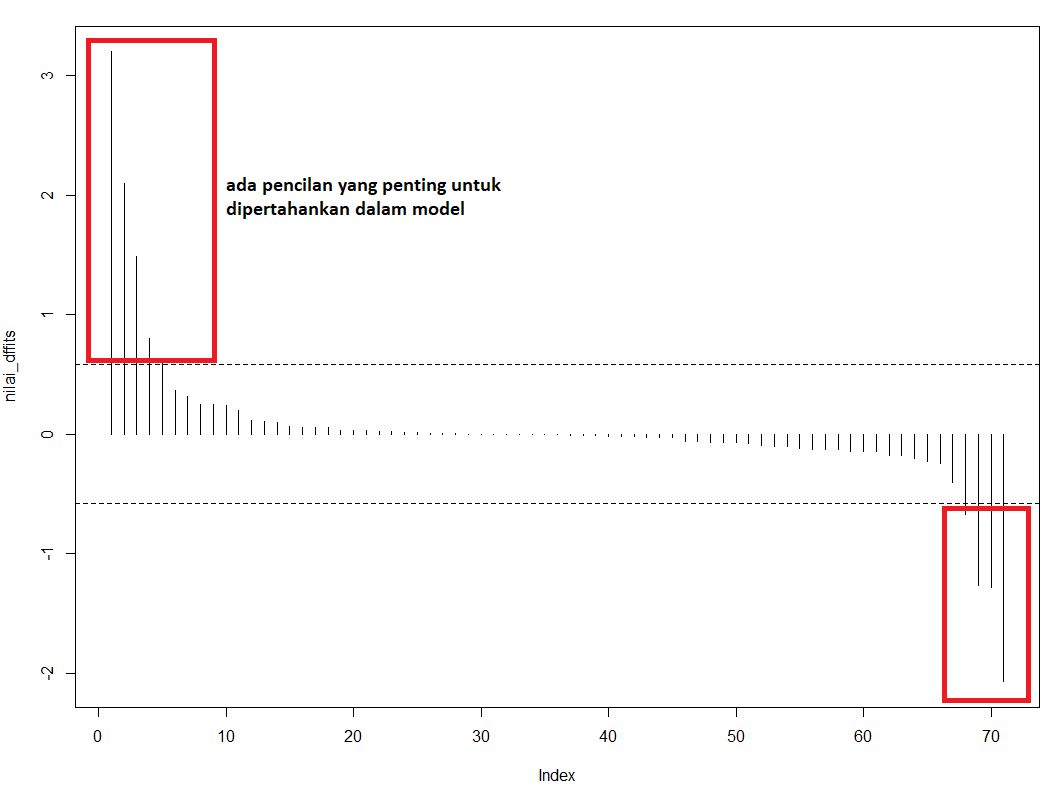 |
| Deteksi seberapa penting pencilan dipertahankan dalam model dengan DFFITS |
Code:
#Model Robust dengan Package robustbase
library(MASS)
#Model Robust M dengan MASS
model_robm <- rlm(grossinc ~ rating + ur + cr + duration + metascore + votgross,
data = dataku, method = "M")
#Ringkasan Model Regresi Robust M
coeftest(model_robm)
Hasil:
z test of coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 7.2767e+01 5.2491e+01 1.3863 0.16567
rating -4.4967e+00 5.6332e+00 -0.7983 0.42472
ur 9.4721e-04 5.0923e-04 1.8601 0.06287 .
cr -2.8914e-01 7.1170e-02 -4.0626 4.852e-05 ***
duration -3.7247e-01 2.9890e-01 -1.2462 0.21270
metascore 3.9549e-01 2.5489e-01 1.5516 0.12076
votgross 8.8656e-04 7.0716e-05 12.5369 < 2.2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Code:
#Model Robust S dengan robustbase
library(robust)
model_robs <- lmRob(grossinc ~ rating + ur + cr + duration + metascore + votgross,
data = dataku, estim = "Initial")
#Ringkasan Model Regresi Robust S
summary(model_robs)
Hasil:
Initial Estimates.
Call:
lmRob(formula = grossinc ~ rating + ur + cr + duration + metascore +
votgross, data = dataku, estim = "Initial")
Residuals:
Min 1Q Median 3Q Max
-66.362 -2.406 1.231 26.437 626.490
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -6.281e+00 1.016e+01 -0.618 0.539
rating 2.333e-01 9.895e-01 0.236 0.814
ur -8.253e-04 1.278e-04 -6.457 1.65e-08 ***
cr 1.375e-01 2.149e-02 6.395 2.11e-08 ***
duration 6.537e-03 5.856e-02 0.112 0.911
metascore -2.668e-02 5.043e-02 -0.529 0.599
votgross 2.347e-04 2.213e-05 10.605 9.90e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 14.56 on 64 degrees of freedom
Multiple R-Squared: 0.7432
Code:
#Model Robust MM dengan robustbase
library(robustbase)
model_robmm <- lmrob(grossinc ~ rating + ur + cr + duration + metascore + votgross,
data = dataku)
#Ringkasan Model Regresi Robust
summary(model_robmm)
Hasil:
Call:
lmrob(formula = grossinc ~ rating + ur + cr + duration + metascore + votgross,
data = dataku)
\--> method = "MM"
Residuals:
Min 1Q Median 3Q Max
-72.332 -4.384 2.157 25.712 600.630
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.082e+01 1.709e+01 -0.633 0.52893
rating -4.637e-02 1.110e+00 -0.042 0.96680
ur -7.160e-04 2.438e-04 -2.936 0.00461 **
cr 9.067e-02 5.030e-02 1.802 0.07618 .
duration 6.083e-02 1.110e-01 0.548 0.58563
metascore 9.439e-02 1.234e-01 0.765 0.44728
votgross 2.651e-04 3.848e-05 6.891 2.89e-09 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Robust residual standard error: 14.82
Multiple R-squared: 0.8386, Adjusted R-squared: 0.8235
Convergence in 17 IRWLS iterations
Robustness weights:
11 observations c(1,2,3,5,8,13,24,27,61,64,67) are outliers with |weight| = 0 ( < 0.0014);
6 weights are ~= 1. The remaining 54 ones are summarized as
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.02519 0.84240 0.98230 0.86700 0.99640 0.99860
Algorithmic parameters:
tuning.chi bb tuning.psi refine.tol rel.tol scale.tol
1.548e+00 5.000e-01 4.685e+00 1.000e-07 1.000e-07 1.000e-10
solve.tol eps.outlier eps.x warn.limit.reject warn.limit.meanrw
1.000e-07 1.408e-03 1.818e-06 5.000e-01 5.000e-01
nResample max.it best.r.s k.fast.s k.max maxit.scale trace.lev
500 50 2 1 200 200 0
mts compute.rd fast.s.large.n
1000 0 2000
psi subsampling cov compute.outlier.stats
"bisquare" "nonsingular" ".vcov.avar1" "SM"
seed : int(0)
Code:
#Perbandingan Model
library(performance)
compare_performance(ols, model_robm, model_robs, model_robmm, metrics = "all")
Hasil:
Name | Model | RMSE | Sigma | R2 | R2 (adj.) | AIC | BIC
-------------------------------------------------------------------------------
ols | lm | 69.289 | 72.980 | 0.748 | 0.725 | 819.326 | 837.427
model_robm | rlm | 70.137 | 73.873 | | | 821.052 | 839.154
model_robs | lmRob | 110.778 | 116.679 | 0.356 | | |
model_robmm | lmrob | 108.100 | 14.817 | 0.839 | 0.823 | |
Demikian sekilas berbagi kita tentang pemodelan regresi robut dengan menggunakan R. Jangan lupa share dan komentar bila ada pertanyaan lebih lanjut. Dan pastinya jangan lupa untuk terus mengikuti dan menyimak unggahan berikutnya dalam blog ini. Selamat mempraktikkan!
Bedanya Regresi Robust dengan Regresi Nonparametrik bagaimana ya pak? Terima kasih
BalasHapusRegresi robust jelas dia dia telah mengikuti sebuah sebaran teoritis normal, sedangkan regresi nonpar, jelas dia regresi yang diasumsikan belum nemu sebaran teoritisnya sehingga dalam praktiknya juga tidak perlu uji asumsi klasik
Hapus